
https://facebook.github.io/prophet/docs/quick_start.html#python-api
Quick Start
Prophet is a forecasting procedure implemented in R and Python. It is fast and provides completely automated forecasts that can be tuned by hand by data scientists and analysts.
facebook.github.io
페이스북이 Prophet(프로펫)이라는 오픈소스 라이브러리를 개발했다
물론~ 내가 코딩공부를 하기 훨씬 오래전에 개발해놓은 라이브러리겠지
날짜별 데이터 예측에 가장 유용한 라이브러리로서, 과거 데이터를 바탕으로 미래 데이터를 예측하는 시스템이다
(뭐 어느 머신러닝이 안그렇겠냐만은.......)
나는 Kaggle에서 제공하는 미국 시카고주 범죄데이터를 바탕으로 범죄율 예측 시스템을 만들어보았는데.....
일단 설명하기 앞서 프로펫 라이브러리를 통해 구현해본 결과.....
겁나 편하다!
prophet 설치방법
#구글코랩은 이미 설치가 되어있기 때문에 아래와 같이 임포트만 해준다
from fbprophet import Prophet
#주피터 노트북
pip install fbprophet
#또는 아나콘다 프롬프트에서
conda install -c conda-forge fbprophet실제로 내가 구현해낸 코드를 아래에 표현해본다
# 구글 코랩환경에서 작성
# 필요한 모듈 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
import seaborn as sns
from fbprophet import Prophet
# 구글드라이브 연동
from google.colab import drive
drive.mount('/content/drive')
# 파일경로지정
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/day18')
# 파일 3개를 각각 저장하고, 사전에 불필요데이터를 삭제시켜준다
chicago_df_1 = pd.read_csv('Chicago_Crimes_2005_to_2007.csv', error_bad_lines=False, index_col = 0)
chicago_df_2 = pd.read_csv('Chicago_Crimes_2008_to_2011.csv', error_bad_lines=False, index_col = 0)
chicago_df_3 = pd.read_csv('Chicago_Crimes_2012_to_2017.csv', error_bad_lines=False, index_col = 0)
# 위 3개파일을 하나로 합쳐준다
chicago_df = pd.concat([chicago_df_1,chicago_df_2,chicago_df_3])
# 이때 merge를 사용해도 될거라 생각되겠지만.... merge는 최대 2개를 합칠때 사용가능하다
# 본격 데이터 가공을 하기 전, 내용물을 잘 살펴본다
chicago_df.head() # 헤드를 열어 어떤형식으로 구성되어 있는지 간략하게 보고
chicago_df.describe() # 요약정보도 한번 봐주고
chicago_df.isna().sum() #NaN 데이터가 있는지 확인해주고
chicago_df.dropna(inplace = True) # NaN데이터 삭제도 해준다
# 본격 데이터 가공 시작
# 데이터학습에 불필요한 컬럼들을 삭제한다
deleted_cols = ['Case Number', 'Case Number', 'IUCR', 'X Coordinate', 'Y Coordinate','Updated On','Year', 'FBI Code', 'Beat','Ward','Community Area', 'Location', 'District', 'Latitude' , 'Longitude']
chicago_df.drop(deleted_cols, axis=1, inplace= True)
# 날짜를 기준으로 데이터를 예측해야하기 때문에 컴퓨터가 읽을 수 있는 날짜형식으로
# 'Date'컬럼을 변환시켜준다
chicago_df['Date'] = pd.to_datetime(chicago_df['Date'], format= '%m/%d/%Y %I:%M:%S %p')
# 'Date'컬럼을 인덱스로 변환시켜준다
# 날짜를 기준으로 학습해야하기 때문이다
chicago_df.index = pd.DatetimeIndex(chicago_df['Date'])
# 월별 범죄 발생건수를 예측하려 한다
# 데이터 프레임을 월별주기로 바꾸고 인덱스를 리셋한다
month_df = chicago_df.resample('M').size()
chicago_prophet = month_df.reset_index()
# prophet 라이브러리를 사용하려면 날짜컬럼은 'ds', 예측컬럼은 'y'로 바꿔야한다
# 라이브러리 제작자가 설정한 필수값이기 때문에 반드시 변경해주어야 한다
chicago_prophet.columns = ['ds','y']
# 예측치를 36개월로 잡고 예측해보자
m = Prophet()
m.fit(chicago_prophet)
future = m.make_future_dataframe(periods = 36, freq = 'M')
forecast = m.predict(future)
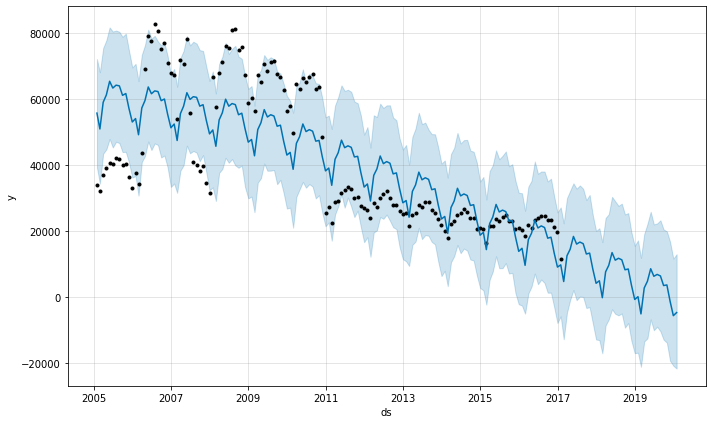
이렇게 라이브러리에 학습시켜 모델을 돌리고나면 최적화된 예측값을 얻을 수 있다
굳이 귀찮게 피쳐스케일링, 노멀라이징을 안해도 된다는 장점은 최고인듯 하다
'& 프로그래밍 > & 머신러닝' 카테고리의 다른 글
| Pandas(판다스) 이해하기 (0) | 2021.03.05 |
|---|---|
| 자주 사용하는 파이썬 라이브러리 모음 (0) | 2021.03.05 |
| ImageDataGenerator [이미지 전처리] (0) | 2021.03.03 |
| Callback 함수 활용하기 (0) | 2021.03.02 |
| Categorical Data Encoding(데이터 전처리 작업) (0) | 2021.03.02 |



