파이썬을 점차 응용하고 활용하면서 numpy를 써보곤 '이건 신세계다' 하면서 점점 재미를 붙였다
그런데 그 재미를 맛본지 일주일도 채 안됐는데.... Pandas를 만났다
엄청 쉽고, 편하고, 심플 그 자체.........
Pandas의 장점
- 기본적인 통계데이터를 제공하여 일단 보기 편하다
- NaN values를 쉽게 조작할 수 있다
- 숫자, 문자열을 알아서 로드하고 이것도 쉽게 조작할 수 있다
- 여러 dataset을 쉽게 merge(합병)할 수 있다
- Numpy와 Matplotlib를 통합한다
# 라이브러리 임포트
import pandas as pd
# 판다스 시리즈 데이터 생성하기
my_data = [30, 6, 'Yes', 'No'] #리스트형식으로 넣어주어야 한다
my_index = ['eggs', 'apples','milk','bread']
pd.Series(data = my_data)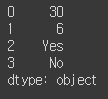
인덱스를 별도로 지정해주지 않았기 때문에, 컴퓨터가 자동으로 할당한 숫자가 인덱스가 되었고,
data값에 my_data를 넣어주어서 그 값이 출력됨을 볼 수 있다
숫자와 문자열이 혼합되어 사용되었기 때문에 dtype이 object로 나옴을 볼 수 있다
groceries = pd.Series(data= my_data, index = my_index)
groceries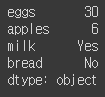
이번엔 데이터시리즈를 만들면서 데이터와 인덱스 값을 모두 지정하였고, 이를 groceries 변수에 저장하였다
출력해보니 인덱스를 각 상품항목으로 지정되었음을 볼 수 있다
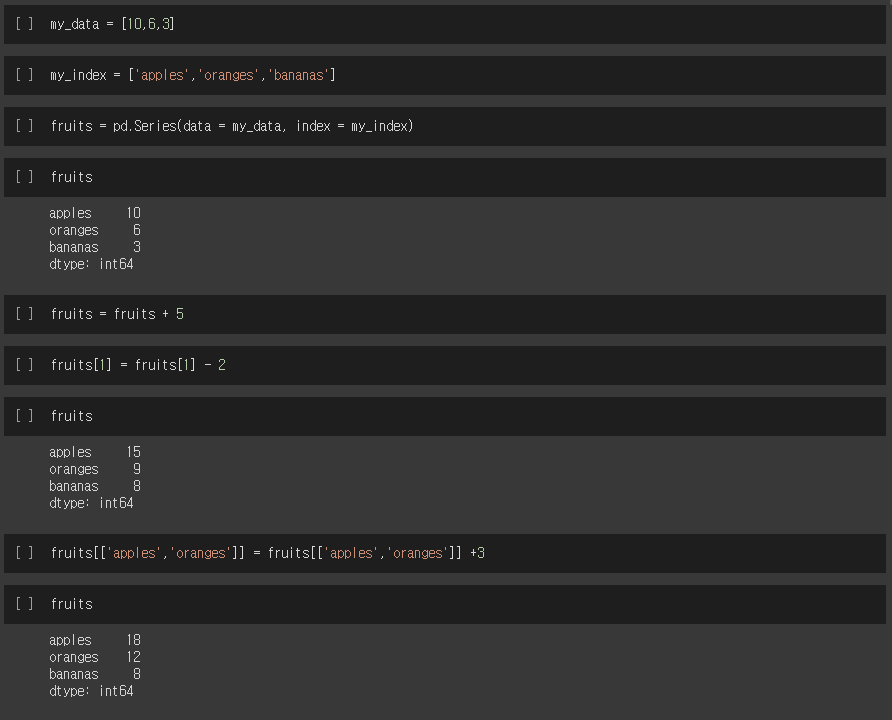
판다스 데이터 시리즈를 만들고 난 후 데이터 안에서 연산처리도 가능하다
다음번엔 판다스에서 원하는 데이터를 가져오는 방법에 대해서 설명할 예정이다
뭐 간략하게 설명하자면 iloc, loc 요론거?
'& 프로그래밍 > & 머신러닝' 카테고리의 다른 글
| 최고의 AI 온라인 교육 프로그램 [엘리스 코딩] (0) | 2021.11.15 |
|---|---|
| AWS Machine Learning Summit 개최 (0) | 2021.05.24 |
| 자주 사용하는 파이썬 라이브러리 모음 (0) | 2021.03.05 |
| Facebook이 개발한 오픈소스 Prophet 라이브러리 사용하기 (0) | 2021.03.03 |
| ImageDataGenerator [이미지 전처리] (0) | 2021.03.03 |



