OpenCV와 Tesseract를 이용한 문자 인식(OCR/테서랙트 설치/구현)
OCR은 'optical character recognition'의 약자로, 이미지나 PDF등 이미 컨버팅 되어 있는 파일 안에서 텍스트를 추출하는
기술이다
가장 대표적인 예로, 주차장에 자동차 번호판 인식기, 번역기 등이 있다
이미지나 영상에서 캡쳐되는 특징을 분석해서 글자를 판독시키는 기술을 반영한다
Tesseract가 text를 분석하는 가장 대표적인 오픈소스이다
윈도우에서 설치하는 방법은 아래와 같다
1. Tesseract 설치
- Tesseract Github에서 코드 클론
- Additional language data 다운로드 (설치방법을 자세하게 공유해주신 블로그 참고)
2. Tesseract OCR 작동 명령어
tesseract image outputbase [-l 언어] [--oem ocrenginemode][--psm pagesmode][configfiles]
# image : ocr을 수행할 이미지 경로
# outputbase : 출력방식 'stdout'바로출력 / 경로+파일명 입력시 txt파일로 저장
# [-l language] : 인식할 언어 'kor'한국어 / 'eng'영어 등(Additional lang을 다운받아야 한다)
# --oem, --psm : 엔진모드와 페이지분할모드 각 명령어 작동방법은 'tesseract --help --extra'3. Tesseract 인식 테스트
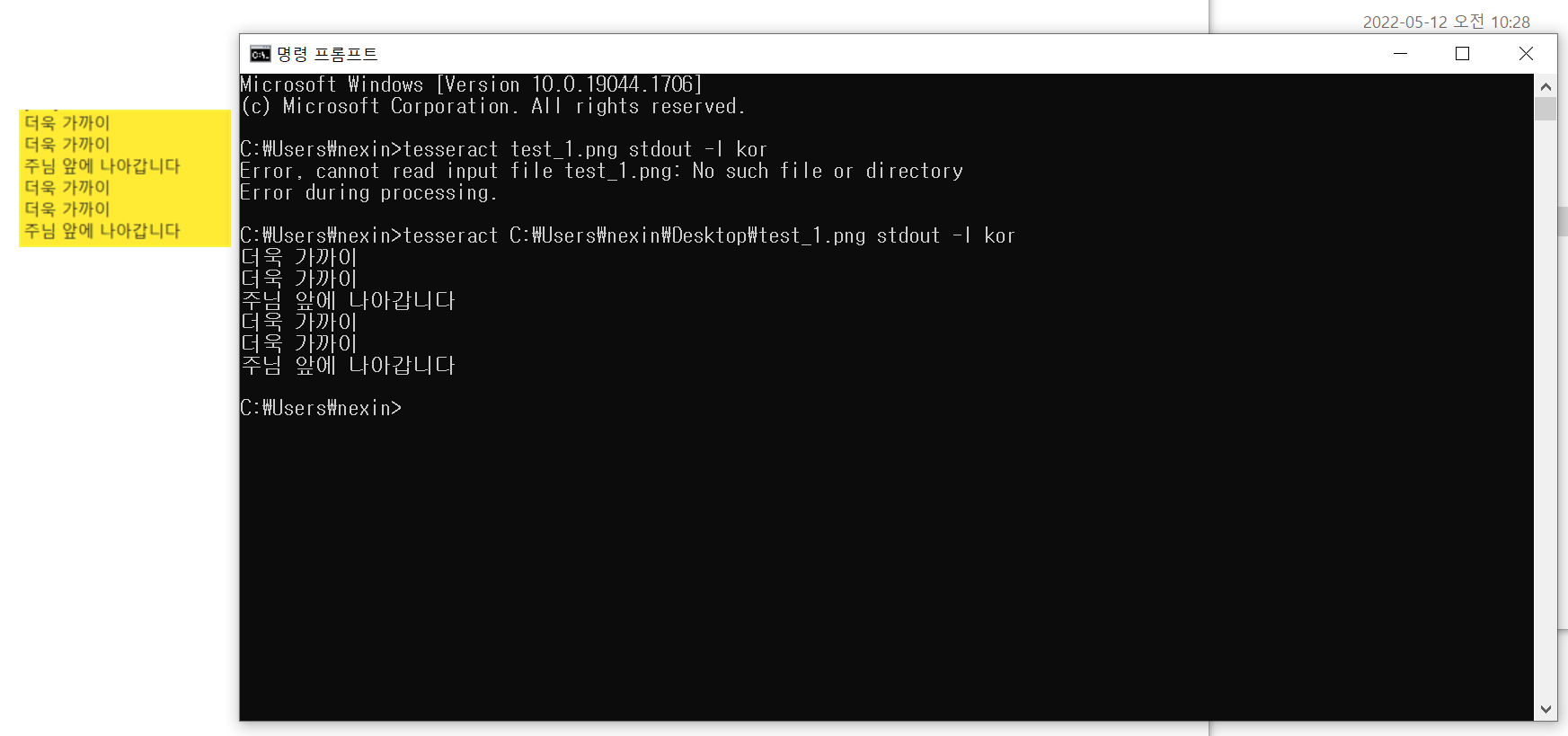
아주 간단한 이미지 파일 하나를 넣어서 tesseract를 구동해보니 생각보다 정확도가 높다
텍스트 인식에는 mnist라는 모듈도 있는데, mnist에 경우에는 단일문자를 분석하는 능력이 높고,
tesseract는 문장력에서 강한 스타일이라고 단순하게 이해하면 좋다
자, 이번에는 파이썬에서 pip install을 이용해서 모듈로서 활용해보도록 하자
파이썬 환경에서 'pip install pytesseract'를 입력해서 모듈을 설치한다
이미지 안에서 내가 지정한 부분만 tesseract를 이용해서 OCR을 작동시켜보는 코드를 한번 만들어보려 한다
# import dependency files
import cv2
import numpy as np
import pytesseract
# 이미지 업로드
img = cv2.imread('test/image.jpg')
# 마우스를 이용하여 이미지에서 원하는 부분을 ROI로 지정한다
x,y,w,h = cv2.selectROI('img',img,False)
if w and h:
roi = img[y:y+h, x:x+w]
cv2.imshow('cropped'roi)
cv2.imwrite('test/cropped.jpg',roi)
# tesseract를 이용해서 ocr을 진행하도록 한다
ocr = pytesseract.image_to_string('test/cropped.jpg',lang='kor')
print(ocr)
cv2.waitKey(0)
cv2.destroyAllWindows()실제 구현결과
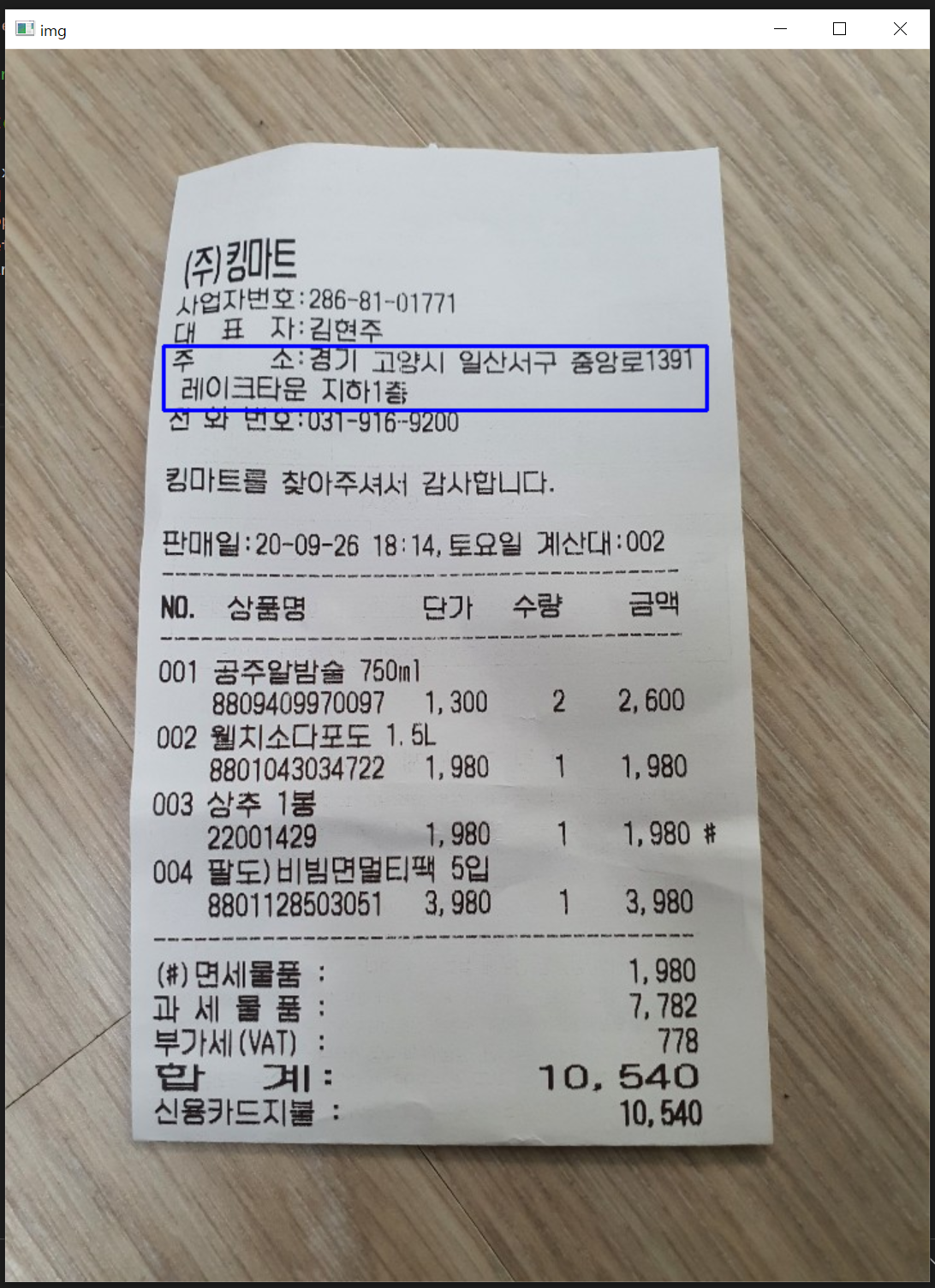
위와 같은 영수증을 파란색 바운딩박스로 roi를 지정했다

crop된 파일을 추출해서 저장한 다음, tesseract로 인식했더니

위와 같은 결과를 가져왔다
분석 결과, 인식률 오차가 생각보다 높았다


간단한 문장도 인식률이 100%는 안되는걸로 보아, 학습 또는 전처리 과정이 필요할 것 같다
일단 오늘은 Tesseract를 어떻게 작동시키는지, 가볍게 알아보았고,
다음부터 opencv와 결합하여 다양하게 tesseract를 고도화 시키는 방법을 알아봐야겠다